
Last week, Meta announced a new audio compression method with artificial intelligence called “EnCodec”. The new method is said to compress audio 10 times more than the MP3 format at 64 kbps without losing quality.
Meta says this technique could significantly improve speech audio quality over low-bandwidth connections, such as phone calls in underserved areas.
The same technique works for music.
Meta announced the technology on October 25 in a paper entitled “High Fidelity Neural Audio Compression”, co-authored by Meta AI researchers Alexandre Defossez, Jade Copet, Gabriel Synnaeve and Yossi Adi. 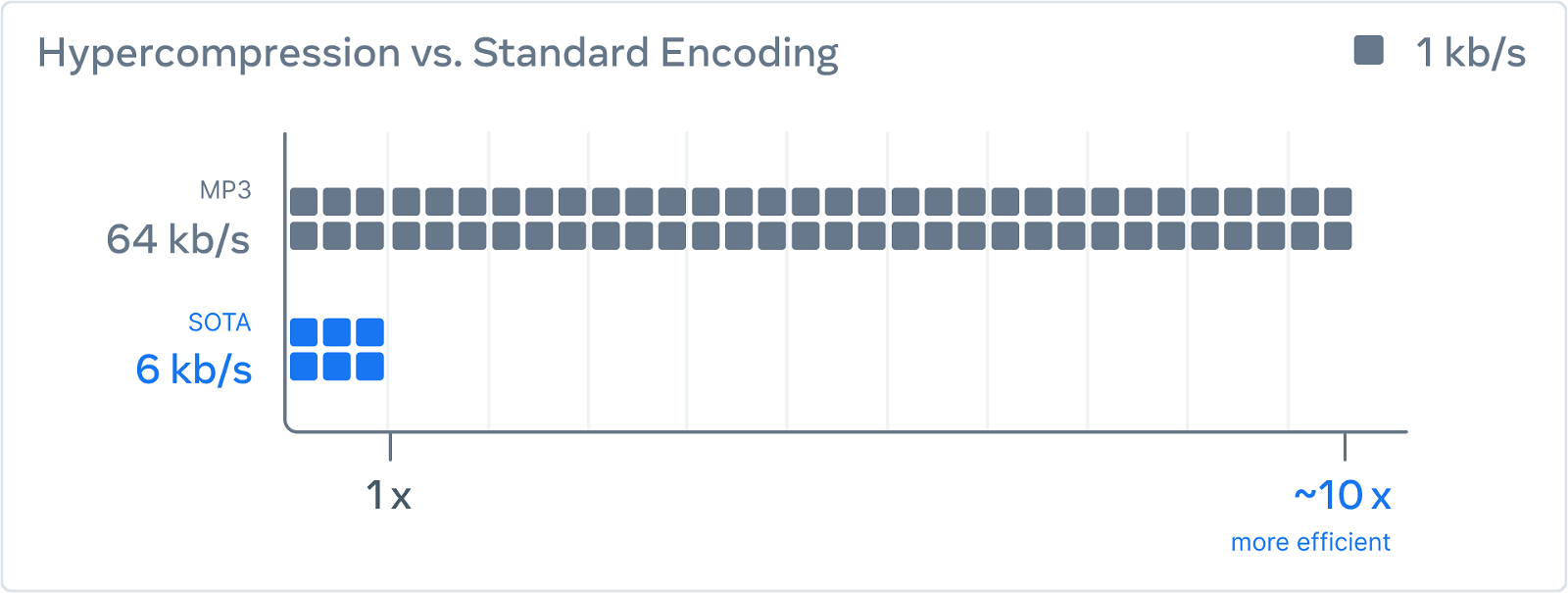
Meta also published a summary of the research on her blog.
The company describes its method as a three-part system that is trained to compress audio to a desired target size. First, the codec converts the uncompressed data into a lower frame rate “latent space” representation.
The “quantizer” then compresses the representation to the target size while finding the most important information that will be used later to reconstruct the original signal. (This compressed signal will be the one sent over a network or stored on disk.) Finally, the decoder converts the compressed data into audio in real time using a neural network on a single CPU.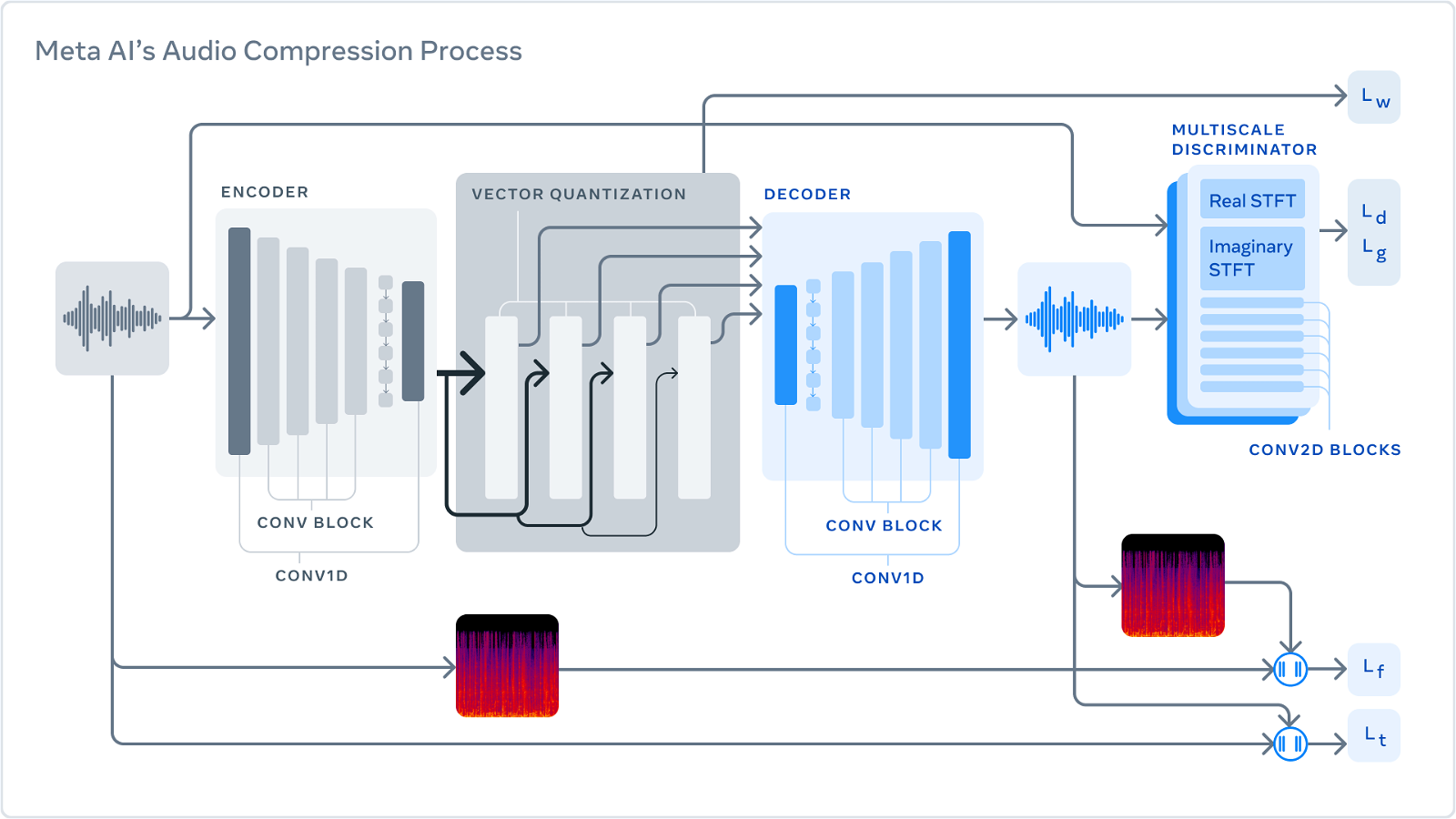
"The key για τη συμπίεση με απώλειες είναι ο localization changes that cannot be perceived by humans. So perfect reconstruction is impossible at low bit rates.”
"To get better results, we use tokens to improve the perceptual quality of the generated samples."
