
On Monday, a group of artificial researchers intelligences from Google and the Technical University of Berlin presented the PaLM-E, ένα πολυτροπικό ενσωματωμένο μοντέλο οπτικής γλώσσας (VLM από το visual-language model) with 562 billion parameters which features vision and speech for robotic control.
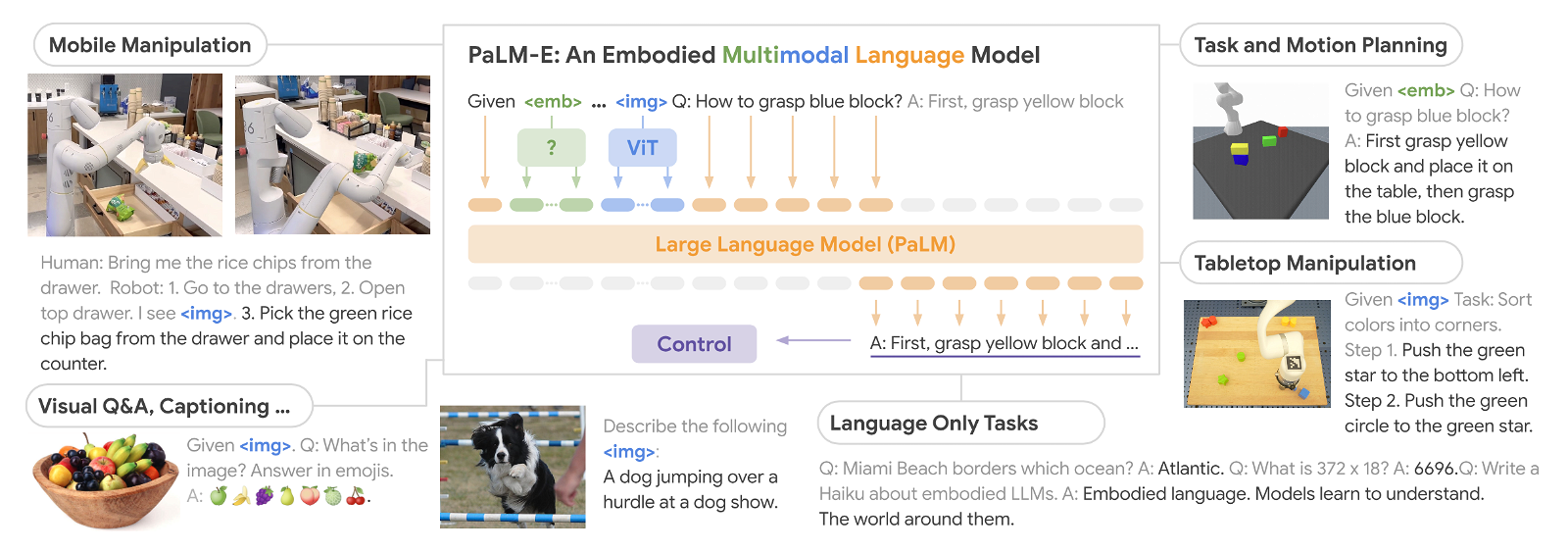
They claim that it is the largest VLM ever developed and that it can perform various tasks without the need for retraining. According to Google, when given a high-level command such as “get me the rice chips from the drawer,” PaLM-E can generate an action plan for a mobile robotic arm platform (developed by Google Robotics) and to perform the actions.
PaLM-E does this by analyzing data from the robot's camera without the need for a pre-processed scene representation. This eliminates the need for a human preprocessing or adding data and enables autonomous robotic control.
For example, the PaLM-E model can instruct a robot to pick up a bag of chips from a kitchen — and with PaLM-E integrated into the control, it can react to any difficulties that may arise during the task. In one video, a researcher grabs the chips from the robot and moves them, but the robot spots them and grabs them again.
In another example, the same PaLM-E model controls itname a robot through tasks with complex sequences that previously required human guidance. The Google Research Paper explains (PDF) how PaLM-E turns instructions into actions.
PaLM-E is the next technology and is called “PaLM-E” because it is based on Google's existing model (LLM) called “PaLM” (which is similar to the technology behind Chat GPT).
Google added sensory information and robotic control to PaLM. Since it is based on a language model, PaLM-E continuously receives data, such as images or sensor data, and encodes it into a sequence that allows the model to “understand” the information in the same way it processes language. In addition to the RT-1 robotics transformer, PaLM-E also draws on data from Google's previous work on the ViT-22B, a vision transformer model unveiled in February. ViT-22B has been trained on various visual tasks such as image classification, object detection, semantic segmentation and image captioning.

I have queries. Again.
Humanity has been struggling for years to build, to create robots. Robots that not too far (in time) will look like humans (i.e. they will have arms, legs, maybe even tools on arms) with the sole purpose of doing the jobs of humans. Okay. so far.
HOWEVER, if all of this becomes reality (which it will, and relatively soon), some will lose their jobs. Whether they are police officers (see the armed robots procured by the US state so that uniformed people are not in danger during the performance of their duties), or industrial robots (including those used by the automobile industry for years), or robot cleaners, or household robots assistants, either mobile assembly robots, motherboards, etc.
Robots – artificial intelligence platforms that will act as lawyers and judges – are also being heard recently.
Good so far ? have we solved the problem of the saying "a human cannot do the precision welding that a robot does"? Let's say yes, with THE FUNDAMENTAL question in the back of our minds.
If another world is laid off, a world that will accumulate in the hundreds of millions of unemployed around the world, if another world also loses its income from whatever work it did and by virtue of its income it consumed goods (and gadgets), who will have economic capacity to buy what the "big guys" who use "cutting edge technologies" will produce?
A possible answer is: we don't need to have so many people...
But another says that: the hungry is and/or becomes a restless beast that cannot be restrained by anything...
We were here.