
Surely you have heard of some strange terms in the world of electronic technology and the internet. One such strange word is web crawler. Let's see what it is and how the whole factory behind it works.

| What is Crawler? |
The web crawler or spider or spiderbot which in Greek is referred to as "web crawler" or "spider" is a program that circulates on the internet collecting web pages. Such a program follows every link within a web page, registering every link and page, until it reaches a dead end. Then start over with a new website.
That is, it is a bot or in Greek one internet robot, που τριγυρνάει το διαδίκτυο ανιχνεύοντας συνδέσμους και ιστοσελίδες, και χρησιμοποιείται συνήθως από διάφορες search engines (Google, Bing, etc.), in order to gather data for their database, so that when you search for something, they can quickly show you the most relevant search results. The work done by the crawler is called crawling.
| What is crawling |
Websites and all webmasters know that search engine crawlers regularly visit their website to see if there are any changes or updates since they last visited it.

If there are any changes or updates, then they update the search engine database (Intexing) with the new content and the new backlinks. Simply put, Indexing is the process of adding a search engine webpage to its data.
The crawler of Google and any other search engine does not work in real time, so there is a delay in capturing the actual search results. This delay can last from a few hours to weeks, depending on how fast the new data will be crawled and updated.
On websites that have more frequent or daily updates, such as a news website, the crawling process is almost daily and it often takes a few minutes for a new page or a new article or a new video to be indexed in Google Index.
For example, an article that was uploaded to a newspaper's website at 10 and 20 will logically appear in search results at 10 and 21. This means that crawling is done almost every minute, due to the nature of the website.
| How web crawling works |
In principle, each search engine uses its own crawler. When they find a website, the first thing they do is download a small file, robots.txt. This file contains the rules that crawlers should follow, for which content they will access and which will not.
A typical robots.txt from a web page should look like this:
Host: https://iguru.gr
User-agent: *
Disallow: /wp-admin/
Allow: *.css
Web crawlers then use a set of rules and algorithms to determine how often they will visit your website, which pages they will access, and which ones they will add to their index.
If you already have a website you will surely be wondering if yours has a robots.txt file to guide search engine robots. Ready-made websites that are for large CMS (such as WordPress, Joomla, etc.) have such a file pre-installed. Only if you have built your own website or have used a custom website built with code, then you probably do not have and you will have to add it manually.
| Briefly so far |
Crawlers: An automated search engine that constantly searches for information on the Internet.
Crawling: The crawler search process
Indexing: Listing what the crawler finds in a huge search engine database.
processing: The process is done by the search engine to search in its database the data that matches a user search. When you search for something on Google, the search engine uses an algorithm to calculate which data fits.
Retrieving: The presentation of the results to the user. The search engine uses an algorithm to present the search results to the user. Nobody knows how just how the algorithm of each search engine works.
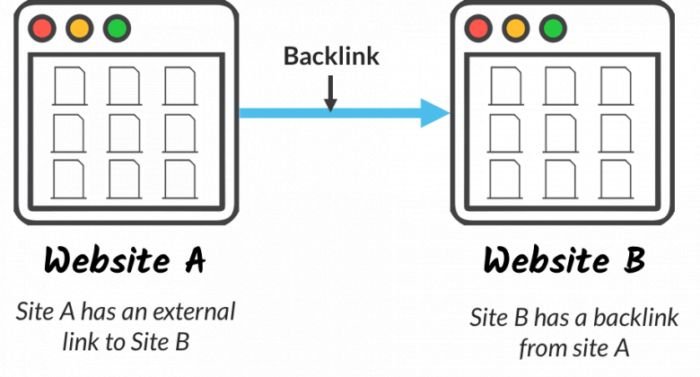
Backlinks: Links to you from an external site. They are created when a foreign website links to your website using a hyperlink. When you put a link to another page then for you this link is called external link and for the other page it is called backlink.
| What exactly are Web Crawlers looking for? |
Web crawlers search the web for:
- Backlinks
- XML Sitemaps
- Images, videos, sounds, and general non-text files
From the pictures οι web crawlers λαμβάνουν τα meta δεδομένα της εικόνας όπως το εναλλακτικό κείμενο. Μέσω των backlinks προσπαθούν να ανακαλύψουν νέα urls και νέα backlinks. Το xml sitemap ή αλλιώς xlm χάρτης ιστοτόπου είναι ένα αρχείο σε μορφή xml που περιέχει αναλυτικά όλα τα urls ενός ιστοτόπου σας καθώς επίσης και συμπληρωματικές πληροφορίες για αυτά. Αυτές οι πληροφορίες αποδίδονται μέσα από συγκεκριμένα πεδία (tags) του xml αρχείου και ενημερώνουν τις μηχανές αναζήτησης για τη gravity (importance) of each url, the renewal rate of the content etc.
In order for a website to rank on the Internet, it must have at least one backlink from another website that has already been accessed by robots and is already ranked in search engines.
| How to check if your website is listed on Google |
If you have a website and do not know if it is listed on Google, you can do the following very simple check:
Go to the Google search bar and type: site: η_ιστοσελίδα_σας.gr
If you get a search result in which your website also appears, then there is no problem. Your site is ranked in the search engines. If not then you need to take the necessary steps to get your website up and running.
| The battle of publicity and search results |
The big bet for webmasters is to be able to make Google algorithm display their own webpage at least on the first page of results.
Google is the first choice in relation to the search engines Bing, DuckDuckGo etc, because it is the one used by most people and consequently offers better advertising performance. The more people search through Google, the more effective your ad will be, but also the more people will be led to your website if it appears on the first page of search results.
Nobody knows how Google's algorithm "thinks". That is, when you search for a term, it returns its results in that order. Of course, the first results win the most clicks, so if your website is in the first places, the more traffic you will have.
And here comes a new service called SEO. The Search Engine Optimization (SEO) or in Greek "Website Optimization for Search Engines" are the processes of optimizing the structure, content and technical characteristics of a website, so that it is friendly to users and internet search engines.

And since the algorithm of each search engine has a secret way operation of so SEO service has a big money cost to raise you in popularity. The most expensive of these are likely to work "closely" with the best search engines and the whole duo works in a complementary way.
| Epilogue |
Web Crawler is a program that pre-searches the internet for web pages. Crawling is a process that is performed automatically and in an unsuspecting time by search engines for almost all websites that exist on the internet.
All webmasters (at least the legitimate ones) want to be seen by Web Crawlers because that way they can be known to a wider audience.
